Mois de l'assembleur x86, semaine 2 - Premiers Pas
Le mois de Juin prend une saveur particulière cette année sur le blog du Hackfest, en effet, quatre articles sur la programmation assembleur seront publiés, un à chaque semaine, et le mois sera couronné d’une présentation HackerSpace sur le sujet. Espérons que vous y apprendrez quelque chose! Voici le deuxième article de cette série sur le sujet. Les articles de la semaine 1 et semaine 3 sont aussi disponibles.
Retour sur la semaine dernière
La semaine dernière, nous avons parlé des différents registres du processeur x86 et de leur utilité respective. Nous avons aussi discuté de la mémoire et des bases de son fonctionnement. Il est fortement conseillé, à ceux qui ne se souviendraient plus de ces éléments, de retourner lire l’article précédent avant d’entreprendre la lecture du présent article.
Cette semaine
Cette semaine, nous allons parler de la structure de base des applications. En plus de cette structure, nous allons commencer à parler de l’utilisation du langage assembleur et d’un debogueur pour être en mesure de voir le bon fonctionnement de nos applications. À la fin du présent article, vous aurez écrit une première application assembleur, vous l’aurez aussi debuguée et exécutée (bien que celle-ci n’affichera rien...).
Structure d’un programme
Les projets assembleurs que nous allons faire suivront tous la même structure. Ainsi, les fichiers .s (extension de fichier utilisée pour le code source asm) que nous allons créer seront tous divisés en plusieurs sections. Ces sections ont pour objectif de renseigner le compilateur sur la nature des données présentes à l’intérieur d’une section donnée. La figure suivante montre un exemple de modèle de projet assembleur que vous pourriez utiliser pour suivre les exemples que nous allons programmer.
Fichier template.s
|
/* Modèle de projet ASM */ .section .data #Les variables initialisées viennent ici .section .rodata #Les variables initialisées ici sont en lecture seule .section .bss #Les variables non initialisées viennent ici .section .text #Le code vient dans la section text .globl _start #Le label _start est disponible globalement (à l’extérieur du binaire) _start: #Label _start, le code qui suit sera exécuté, c’est notre point d’entrée #LE CODE VIENT ICI |
Une lecture du fichier template.s montré à la figure précédente permet de voir qu’il y a principalement quatre sections dans le fichier en question. Toutes ces sections ont un objectif bien précis. Vous noterez au passage, l’utilisation de /* */ et de # pour signifier des commentaires.
La première section, .data, est la section à l’intérieur de laquelle les variables globales de notre application seront déclarées et initialisées. Les variables déclarées dans cette section sont disponibles pour le programmeur en lecture et en écriture.
La deuxième section, .rodata, est semblable à la première à l’exception que les variables déclarées et initialisée dans cette section sont disponibles en lecture seule. Une tentative de modification de ces données provoquera une “segmentation fault”.
La troisième section, .bss, est elle aussi semblable à la section .data à l’exception que les variables déclarées dans cette section ne sont pas initialisées lors de la déclaration. Ainsi, le programmeur devra initialiser ces variables aux bonnes valeurs avant d’en faire usage. Bref, la section .bss permet surtout de “réserver” de l’espace mémoire qui sera utilisée pendant l’exécution de l’application.
La dernière section dont nous allons parler est la section .text. C’est la section qui contient le code de l’application. C’est dans cette section que les instructions en assembleur seront écrites dans le but d’être exécutées par le processeur de votre station de travail. Vous pouvez même voir que certains éléments sont déjà présents dans cette section. La première instruction de la section, l’instruction .globl _start a pour objectif de rendre le libellé _start accessible au “linker” (on en reparle). Grossièrement expliqué, cela veut simplement dire que le code contenu dans le libellé pourrait être utilisé par d’autres applications. La deuxième instruction, l’instruction _start:, indique seulement la présence d’un label. Encore une fois, grossièrement dit, on peut comparer la présence d’un tel label à une déclaration de fonction ou de procédure. Mais attention, ça reste très “grossièrement” dit... Le code qui suit le label _start sera exécuté quand on demandera l’exécution du label _start. Parlant de ce label, le nom de ce label est important. Le label _start représente le point d’entrée dans votre application. C’est un peu comme la fonction int main() en programmation C.
Première application en assembleur
Il est donc temps de se lancer dans notre première application en assembleur. Cette application est assez simple et ne procède à aucun affichage. Le but de ce petit projet est surtout de procéder à l’ensemble des étapes de compilation de l’application et d’apprendre les bases de gdb (le débugueur gnu). Ce projet permet aussi de se familiariser avec l’utilisation de certains concepts qui nous suivront pendant toute la série d’articles. Ainsi, notre premier projet ne comportera que deux section, la section .data et la section .text.
Le code de la section .data est assez simple. La figure suivante montre l’implémentation du code de cette section pour le présent exercice.
|
.section .data nbPommes: .int 255 |
Comme vous pouvez voir, cette section, hormis la déclaration de la section elle-même, comporte seulement deux lignes de code. la première, le label nbPommes: est utilisé pour indiquer un nom pour la zone de mémoire déclarée sur la ligne suivante. Notez l’utilisation du terme “zone mémoire”. Il faut savoir que, en assembleur, tout (ou presque) n’est que pointeur ainsi, une bonne compréhension des concepts de pointeurs est importante. Le présent article se veut aussi une petite révision sur la question. La ligne suivante, .int 255 permet de “typer” notre zone mémoire et de lui assigner une valeur. Dans notre cas, la zone mémoire sera un entier dont la valeur sera le nombre décimal 255. Ces deux lignes pouraient donc être traduites comme:
int nbPommes = 255;
Si nous utilisions le langage C.
La section .text comportera quant à elle un peu plus de code. La figure suivante présente le code de cette section
|
.section .text #Le code vient dans la section text .globl _start #Le label start sera disponible pour le linker _start: #Label _start, le code qui suit sera exécuté movl $nbPommes, %eax addl $50, (%eax) incl (%eax) #fin de l'application #c'est un peu l'équivalent du #return 0 à la fin de #la fonction main() en C #Nous reviendrons sur ce genre d'appel #dans un prochain article movl $1, %eax movl $0, %ebx int $0x80 |
Avant tout, il faut savoir que les trois dernières lignes de code à la fin de l’application ne nous concernent pas pour le moment. Nous y reviendrons dans un article prochain. Cependant, si elles vous intéressent, vous pouvez faire une petite recherche sur google pour “Linux system calls”. Vous y trouverez réponses à vos questions. Ainsi, en réalité, pour le moment, seulement trois lignes de code nous intéressent soit les lignes:
|
movl $nbPommes, %eax addl $50, (%eax) incl (%eax) |
La première instruction utilisée, movl permet de déplacer une information de 32 bits d’une source à une cible. Dans le cas présent, la source est l’adresse mémoire de notre variable nbPomme déclarée et initialisée dans la section .data. La destination, dans notre cas, est le registre d’usage général eax ici représenté avec la notation %eax. Note importante, l’utilisation du signe $ est faite pour indiquer les opérandes “immédiates”. Ainsi, les constantes et les variables sont précédées de ce signe lors des opérations faites sur ces dernières. Cela permet au compilateur de comprendre qu’il ne sagit pas d’élément du du processeur mais bien de valeurs qui lui sont directement fournies. Le signe % est quant à lui utilisé comme préfixe lors de l’utilisation d’un registre. L’utilisation de ces deux caractères est propres à la syntaxe AT&T. La syntaxe Intel n’utilise pas ces symboles pour cet usage. Alors, de retour à l’instruction movl. Le cas présent montre que $nbPommes est placé dans le registre %eax. En réalité, c’est l’adresse à laquelle on retrouve la variable nbPommes qui est positionnée dans le registre %eax.
L’instruction suivante, addl, permet de faire une opération d’addition. dans le cas présent, on ajoute la valeur décimale 50 à ce qui se trouve à l’adresse sur laquelle pointe le registre %eax. L’utilisation des parenthèses autour de l’indicateur de registre %eax est ici faite comme opérateur de déréférencement, un peu comme l’étoile en programmation C. Ainsi, l’addition sera faite, non pas sur ce qu’il y a dans le registre %eax mais bien à l’adresse mémoire vers laquelle pointe le registre %eax. La figure suivante montre la relation entre le contenu du registre et la case mémoire vers laquelle le registre pointe à ce moment du programme.

Dans l’éventualité où l’opérateur de déréférencement n’était pas utilisé, le processeur ne pourrait pas savoir que nous voulons en réalité faire l’addition sur la case mémoire vers laquelle pointe le registre EAX. L’opération serait donc faite directement sur le registre EAX lui-même tel que le montre la figure suivante.

Le lien entre le registre EAX et la case mémoire contenant la valeur 255 serait donc brisé puisque le registre ne contiendrait plus l’adresse de la case mémoire. Dans la situation ou la case mémoire pointée serait une zone mémoire acquise de manière dynamique, il en résulterait une “fuite de mémoire”. Ainsi, si on veut faire l’addition sur la valeur contenue dans la case mémoire vers laquelle pointe le registre EAX, il est important d’utiliser les opérateurs de déréférencement. La figure suivante montre le résultat de l’éxécution correcte de l’opération d’addition sur la case mémoire et non pas sur le registre.

La dernière ligne du programme (en ne comptant pas les trois dernières...), incl (%eax) est simplement utilisée pour incrémenter de 1 la valeur de la case mémoire. Notez l’utilisation de l’opérateur de déréférencement.
Ainsi, notre petit programme ne fait pas grand chose comme on dit! Mais il nous a permis, déjà, d’apprendre et de mettre en pratique plusieurs éléments important du langage assembleur. Pour les adeptes de C, la figure suivante présente un petit programme C effectuant sensiblement les mêmes opérations. Notez que le registre EAX y a été représenté par une variable du même nom afin d'aider à la compréhension de l'exemple seulement. Ce programme est uniquement présenté pour facilité la compréhension et l’assimilation des concepts de programmation en assembleur.
Version C
|
int nbPommes = 255; int *eax; int main(){ eax = &nbPommes; *eax = *eax + 50; *eax++; return 0; } |
Vous pouvez donc voir que la version assembleur de ce petit programme n’a rien de plus compliqué que la version C de l’application. Il suffit simplement de s’habituer à la syntaxe un peu inhabituelle des langages assembleurs. Une fois cette étape franchie, rien n’est très compliqué en assembleur.
Il est maintenant temps de faire fonctionner notre application.
Traduction en “opcodes” et “linking” de l’application
Avant d’être en mesure d’exécuter l’application que nous venons tout juste de programmer, il reste deux étapes. La première consiste à traduire le code assembleur en code binaire que l’ordinateur sera en mesure de comprendre. Par la suite, le fichier binaire créé doit être lié avec toutes les librairies qui auraient pu être utilisées en cours de développement de l’application. Le graphique suivant résume ces étapes.
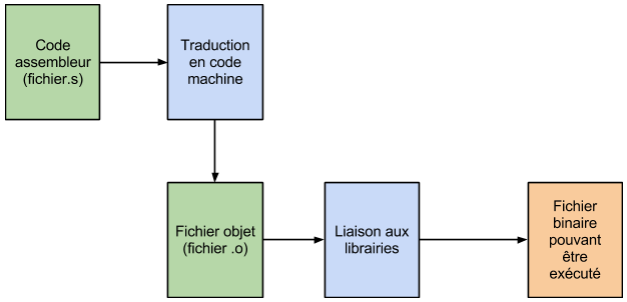 Ainsi, dans le but de faire fonctionner une application, après son écriture, deux actions doivent être posée par le programmeur. Ces deux actions se résument en deux commandes exécutées sur la ligne de commande. Ces deux commande sont présentées à la figure suivante.
Ainsi, dans le but de faire fonctionner une application, après son écriture, deux actions doivent être posée par le programmeur. Ces deux actions se résument en deux commandes exécutées sur la ligne de commande. Ces deux commande sont présentées à la figure suivante.
|
$ as -gstabs --32 functionPlay.s -o functionPlay.o $ ld -m elf_i386 functionPlay.o -o functionPlay |
Les deux commandes permettent la préparation d’un binaire 32 bits. Pour la première commande, nous avons utilisé trois options, l'option --32, l’option --gstab et l’option -o. L'option -gstabs permet d’ajouter des éléments au fichier résultant afin de faciliter le “debuguage” de l’application résultante. L'option -o permet simplement de spécifier le nom du fichier de sortie. L'option --32 permet d'indiquer que nous désirons compiler l'application en mode 32 bits. En ce qui concerne la deuxième commande, la commande ld, l’option -o possède le même effet que l'option -o de la commande as. En ce qui concerne l'option -m elf_i386, son objectif est de spécifier que nous travaillons avec un format de fichier 32 bits. Nous reviendrons sur cette commande lorsque nous utiliserons des fonctions C à l’intérieur d’applications ASM.
Suite à ces deux commandes, le fichier résultant est prêt à être exécuté! Ou plutôt débugué dans notre cas ;)
Comme notre application ne procède à aucun affichage, nous utiliserons le debugueur gdb pour s’assurer que celle-là fonctionne correctement. Avant d’aller plus loin, assurez-vous d’avoir la dernière version de gdb sur votre station de travail. Certaines anciennes version ont des problèmes avec la mise en place de break points.
Utilisation de base de gdb
Pour lancer une application dans gdb, il suffit de lancer la commande gdb suivie du nom du fichier binaire devant être débugué. Dans mon cas, cela résulte en la commande présentée à la figure suivante.
|
$ gdb movingDataProject |
Suite à l’exécution de cette commande, nous sommes projetés dans l’environnement du debugueur. Il est possible de lancer l’application à l’aide de la commande run. La figure suivante montre l’exécution de notre application dans gdb lorsque la commande run est lancée.
|
(gdb) run Starting program: /home/philippe/Documents/PersonalProject/2013/ASM_Month/code/movingDataProject [Inferior 1 (process 3833) exited normally] (gdb) |
Comme vous pouvez le voir, il ne s’est pas passé grand chose! Comme notre application est très simple et qu’il n’y a aucune interaction avec l’utilisateur, gdb a terminé l’exécution sans vraiment donner la chance au programmeur d’analyser le comportement du code de son application. Pour être en mesure de “voir” l’exécution de notre application, nous allons y positionner des break points. Les break points vont nous permettre de mettre l’application en pause afin d’analyser son comportement. Ces break points peuvent être mis sur des numéros de lignes ou sur des nom de label. Il est aussi possible de faire des brake points conditionnels. Dans notre cas, nous allons ajouter un brake point sur le label _start. Cela va nous permettre d’analyser notre application depuis le début de l’exécution du code. Pour ajouter un brake point, il suffit d’utiliser la commande break. La figure suivante montre l’ajout d’un brake point sur le label _start.
|
(gdb) break _start Breakpoint 1 at 0x4000b0: file movingDataProject.s, line 18. (gdb) |
Une fois le brake point ajouté, il est possible de commencer à debuguer notre application. Nous allons lancer l’application, à l’aide de la commande run. Observez bien la différence.
|
(gdb) run Starting program: /home/philippe/Documents/PersonalProject/2013/ASM_Month/code/movingDataProject Breakpoint 1, _start () at movingDataProject.s:18 18 movl $nbPommes, %eax (gdb) |
Comme vous pouvez le voir, l’application est en pause sur notre break point. La ligne de code affichée est la prochaine ligne de code devant être exécutée. À ce moment, pour continuer l’exécution, deux possibilité s’offre à nous. Nous pouvons soit continuer l’exécution jusqu’au prochain brake point avec la commande continue ou continuer l’exécution “ligne par ligne” avec la commande next. Comme nous n’avons pas d’autre break point, nous utiliserons la commande next. Cependant, juste avant, nous allons regarder l’état des registres de notre processeur. Il est possible d’afficher les registres à l’aide de la commande info registers. La figure suivante montre le résultat de l’exécution de cette commande dans mon environnement de travail.
|
(gdb) info registers rax 0x0 0 rbx 0x0 0 rcx 0x0 0 rdx 0x0 0 rsi 0x0 0 rdi 0x0 0 rbp 0x0 0x0 rsp 0x7fffffffe1f0 0x7fffffffe1f0 r8 0x0 0 r9 0x0 0 r10 0x0 0 r11 0x200 512 r12 0x0 0 r13 0x0 0 r14 0x0 0 r15 0x0 0 rip 0x4000b0 0x4000b0 <_start> eflags 0x202 [ IF ] cs 0x33 51 ss 0x2b 43 ds 0x0 0 es 0x0 0 fs 0x0 0 gs 0x0 0 (gdb) |
Vous remarquerez probablement qu’aucun registre (autre que les registres de segment) ne portent le même nom que les registre donc nous avons parlé lors du précédent article (ceci ne sera pas le cas si vous avez utilisé les options 32 bits lorsque vous avez généré le fichier binaire). En fait, c’est tout à fait normal puisque je n'ai pas compilé le code en 32 bits lorsque j'ai préparé l'exemple. Les registres 64 bits sont préfixés de la lettre r et non pas de la lettre e qui représente les registres 32 bits. Ainsi, le registre eax devient rax lorsque nous sommes en 64 bits. Dans le cas actuel, l'application fonctionnera quand même sans aucun problème, attention, ce ne sera pas toujours le cas. Aussi, avant d’aller plus loin, la commande print de gdb sera très utile. Cette commande permet d’afficher une valeur tel que le montre la figure suivante.
|
(gdb) print nbPommes $1 = 255 (gdb) |
Il est donc possible d’afficher la valeur de nos variables à partir du debugueur. Nous allons donc faire la commande next suivie de la commande info registers pour voir le résultat de l’exécution de notre première ligne de code.
|
(gdb) next 19 addl $50, (%eax) (gdb) info registers rax 0x6000c8 6291656 rbx 0x0 0 rcx 0x0 0 rdx 0x0 0 rsi 0x0 0 rdi 0x0 0 rbp 0x0 0x0 rsp 0x7fffffffe1f0 0x7fffffffe1f0 r8 0x0 0 r9 0x0 0 r10 0x0 0 r11 0x200 512 r12 0x0 0 r13 0x0 0 r14 0x0 0 r15 0x0 0 rip 0x4000b5 0x4000b5 <_start+5> eflags 0x202 [ IF ] cs 0x33 51 ss 0x2b 43 ds 0x0 0 es 0x0 0 fs 0x0 0 gs 0x0 0 (gdb) |
Comme vous pouvez le voir, nous avons avancé d’une seule ligne. Vous pouvez aussi remarquer que la valeur du registre eax (rax) a changée. Ce registre pointe maintenant sur la case mémoire qui loge la variable nbPommes. La commande print nbPommes peut vous confirmer que la valeur de cette variable est toujours 255.
|
(gdb) print nbPommes $2 = 255 (gdb) |
La prochaine commande à être exécutée est une opération d’addition, encore une fois, nous allons faire la commande next et afficher l’état des registres.
|
(gdb) next 20 incl (%eax) (gdb) info registers rax 0x6000c8 6291656 rbx 0x0 0 rcx 0x0 0 rdx 0x0 0 rsi 0x0 0 rdi 0x0 0 rbp 0x0 0x0 rsp 0x7fffffffe1f0 0x7fffffffe1f0 r8 0x0 0 r9 0x0 0 r10 0x0 0 r11 0x200 512 r12 0x0 0 r13 0x0 0 r14 0x0 0 r15 0x0 0 rip 0x4000b9 0x4000b9 <_start+9> eflags 0x212 [ AF IF ] cs 0x33 51 ss 0x2b 43 ds 0x0 0 es 0x0 0 fs 0x0 0 gs 0x0 0 (gdb) |
Comme vous pouvez le voir, nous avons avancé d’une ligne. La valeur du registre eax (rax) n’a pas changée. Par contre, la commande print nbPommes va nous permettre de voir que l’addition a bel et bien été effectuée, non pas sur le registre eax mais bien sur les informations contenues à la case mémoire sur laquelle pointe le registre eax.
|
(gdb) print nbPommes $3 = 305 (gdb) |
La suite devrait maintenant être évidente pour vous! Lorsque vous avez terminé, vous pouvez faire la commande continue suivie de la commande quit pour sortir du débugueur.
|
(gdb) continue Continuing. [Inferior 1 (process 3871) exited normally] (gdb) quit |
Notez, qu’il aurait été possible d’écrire le programme de manière à ne pas avoir à travailler avec l’adresse contenant l’information relative au nombre de pommes. La figure suivante montre une autre version de l’application dans laquelle il n’est pas nécéssaire d’utiliser l’opérateur de déréférencement. Vous noterez cependant qu’une opération supplémentaire est requise pour faire fonctionner l’application.
|
.section .data nbPommes: .int 255 .section .rodata .section .bss .section .text .globl _start _start: nop movl nbPommes, %eax addl $50, %eax movl %eax, nbPommes movl $1, %eax movl $0, %ebx int $0x80 |
L’interprétation de cette nouvelle version est laissée à vos propres soins. Avec vos connaissances nouvellement acquises, vous ne devriez pas avoir de mal à comprendre ce qui se produit dans cette nouvelle version de l’application.
C’est ainsi que se conclut le deuxième article de cette série! Lors du prochain article, nous allons voir comment diriger la logique d’exécution d’une application en assembleur. D’ici là, n’hésitez pas à nous contacter avec toutes les questions que vous pourriez avoir!
Ps: Pour ceux d’entre vous qui aimeraient avoir un “cheat sheet” pour gdb, en voici un:
http://www.cs.berkeley.edu/~mavam/teaching/cs161-sp11/gdb-refcard.pdf