Mois de l'assembleur x86, semaine 1 - Introduction
Le mois de Juin prend une saveur particulière cette année sur le blog du Hackfest, en effet, quatre articles sur la programmation assembleur seront publiés, un à chaque semaine, et le mois sera couronné d’une présentation HackerSpace sur le sujet. Espérons que vous y apprendrez quelque chose! Voici le premier article de cette série sur le sujet. Les articles de la semaine 2 et semaine 3 sont aussi disponibles.
L’assembleur, qui n’a jamais voulu apprendre ce langage un peu cryptique? Malheureusement, bien peu de gens se lancent dans l’apprentissage des langages assembleurs. Une des raisons est probablement la courbe d’apprentissage qui semble assez ardue. Par ailleurs, une croyance populaire disant “il faut beaucoup trop de lignes de code pour faire une application significative” n’aide pas elle non plus à encourager les gens dans l’apprentissage des assembleurs.
La réalité est tout autre!
L’apprentissage d’un langage assembleur est simple, pour autant qu’on s’en donne la peine, et l’écriture d’un programme en assembleur peu très bien être rapide et pas plus compliquée que l’écriture d’un programme C. Il n’y a qu’une seule règle: Patience.
Avant tout, il faut savoir que tous les langages assembleurs sont “faits” pour fonctionner avec une architecture précise. Par exemple, dans le cadre de la présente série d’articles, nous allons discuter d’un langage assembleur fait pour fonctionner avec les processeurs de la famille x86. Le langage que vous allez apprendre à la lecture de ces articles ne pourrait donc pas fonctionner sur un Rasbery Pi puisque ce dernier utilise une architecture ARM possédant son propre assembleur. Les programmes écrits en assembleur ne sont donc pas portables d’une architecture à l’autre.
Comme dans tous bons textes d’introduction à l’assembleur, on n’y échape pas, on doit commencer à la base et parler du processeur lui-même. Comme nous n’écrivons que quatre articles et non pas un livre, l’introduction aux concepts sera assez rapide. Ainsi, nous éviterons de parler des différentes unités internes du processeur et accepterons le niveau d’abstraction au processeur lui-même ainsi qu’à la mémoire sans se préoccuper, pour l’instant, des autres périphériques ou des bus qui relient entre-eux tous ces éléments. Il est important de ne pas oublier que ce texte est une introduction ciblant les programmeurs (et non programmeurs) de tous les niveaux. Ne soyez donc pas choqués si vous considérez le niveau d’abstraction trop élevé (si vous voulez en jaser, vous pouvez toujours me payer une bière au prochain hackerspace :P )...
Le processeur et la mémoire
Votre ordinateur, pour fonctionner, a besoin d’un minimum de composants. Dans notre cas, nous limiterons ces composantes à deux éléments, le processeur et la mémoire. Ces deux éléments sont reliés par un “bus” permettant au processeur d’avoir accès, en lecture et en écriture, aux différentes cases mémoire. Grosièrrement dit, l’ensemble des informations nécéssaires au fonctionnement d’un programme sont conservées dans la mémoire de l’ordinateur. Cela implique donc que les instructions d’exécution ainsi que les différentes variables utilisées pour le fonctionnement des applications sont conservées dans la mémoire. À l’intérieur du processeur, des mesures sont mises en place pour permettre à ce dernier d’obtenir les informations ainsi que les instructions devant être exécutées. Le processeur connait donc, et ce à tout moment de l’exécution, quelle est la prochaine instruction devant être lue et exécutée. L’illustration suivante montre un processeur sur le point d’aller chercher la première instruction en mémoire.
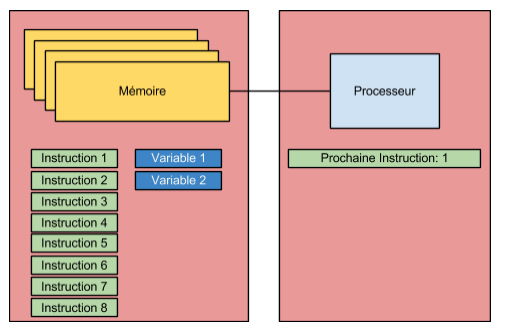
Ainsi, lors de l’exécution de l’application, la zone du processeur (que nous appelons registre à partir de maintenant) responsable de conserver un lien vers la prochaine exécution sera modifiée d’instruction en instruction de manière à toujours être en moyen d’obtenir la prochaine instruction et ainsi continuer l’exécution de l’application. L’illustration suivante montre la deuxième étape du processus d’exécution entamé à l’intérieur de la première illustration.
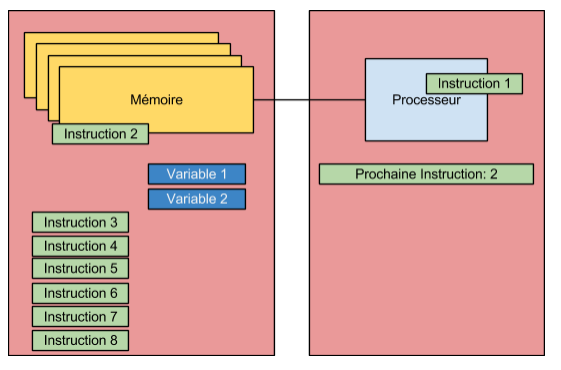
L’exécution de l’application passe donc d’une instruction à l’autre en obtenant les informations de la mémoire. Ainsi, contrairement à ce que plusieurs personnes tendent à croire, le code assembleur n’est pas directement dans le processeur mais bien dans la mémoire. Le processeur obtient cependant les instructions une à une, à partir de la mémoire, et procède à l’exécution de celles-ci selon l’ordre logique établi par l’application. Un programme, assembleur ou non, n’est donc rien d’autre qu’une suite d’instructions lues en mémoire par l’unité centrale de l’ordinateur. Bien entendu, le processeur (dans le cas du x86) possède lui-même une certaine quantité de mémoire (la mémoire cache, d’autres zones existent aussi, dont les registres, on en parle plus loin) qui permet de conserver un certain nombre d’instruction, à l’avance, et ainsi éviter le plus possible les accès direct à la mémoire puisque ceux-ci sont, à l’échelle d’un processeur bien entendu, très lents. Voilà, le concept de base est jeté! En tout temps, souvenez-vous que tout est une question de mémoire. Dans un programme de base, tout est une question de mémoire
Composition du processeur
Tous les processeurs ont une structure. La programmation assembleur permet au programmeur d’ordonner à l’unité centrale d’effectuer des modifications aux éléments présents dans sa structure, principalement, les registres présents à l’intérieur du processeur. Le programmeur pourra donc, par l’entremise des opérations qu’il envoie au processeur, positionner des informations dans les registres afin que d’autres opérations soient en mesure d’utiliser ces informations. Suite aux traitements faits sur les données, le programmeur, toujours à l’aide d’opérations envoyées au processeur, pourra récupérer le résultat des opérations précédentes et ainsi créer la logique de l’application en fonction des besoins de son programme. Les registres sont donc extrêmement importants pour le programmeur assembleur. Il existe plusieurs types de registres. L’illustration suivante présente certains des registres principaux de l’architecture x86. Notez que cette illustration omet volontairement plusieurs registres en plus d’omettre le registre contenant les “flags” du processeur puisque ces flags seront vu en détails lorsque nous utiliserons les instructions du langage ASM et le debugger.. Comme nous reviendrons sur le registre des flags, il n’est pas nécéssaire de les introduire au moment présent. Aussi, comme la majorité des informations disponibles en ligne utilisent les registres en mode 32 bits, nous avons nous aussi, principalement pour les raisons de l’objectif final poursuivi par cette série(surprise surprise, vous verrez au HackerSpace!) décidé d’utiliser les registres en mode 32 bits.
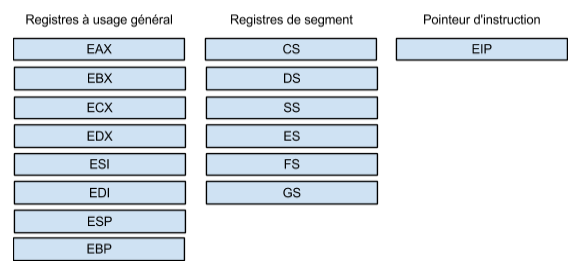
Registres à usage général
Huit registres sont considérés comme étant à “usage général”. Cette appélation est en réalité un peu abusive. En effet, les “normes” établies font que nous ne pouvons, en réalité, faire ce que nous voulons avec l’ensemble de ces registres. Bien entendu, ces “normes” dans certaines situations pourraient être évitée, mais de manière générale, un programmeur, lorsqu’il écrit un programme qui sera exécuté sur un système d’exploitation précis, doit respecter les règles en vigueur dans ce système d’exploitation. Ainsi, aussi pour des raisons de performance (dont nous ne discuterons pas) il est recommandé d’utiliser les registres à usage général pour certaines tâches précises.
EAX
Le registre EAX, est généralement utilisée pour récupérer le résultat des opérations. Par exemple, si une fonction retourne une valeur, cette valeur pourrait être retournée, à la sortie de la fonction, dans le registre EAX.
EBX
Le registre EBX sera généralement utilisé comme index de base lors d’une utilisation avec des tableaux. Ce registre pointera donc généralement vers des données en mémoire.
ECX
Le registre ECX est généralement utilisé comme un compteur. Par exemple, il pourrait être utilisé pour conserver l’index courant lors d’un passage dans un tableau par itération.
EDX
Le registre EDX pointe normalement sur des données en mémoire. Aucune utilisation particulière ne lui est dédiée.
ESI
Le registre ESI est souvent utilisé, lors pour faire des opérations sur les chaînes de caractères, afin de conserver l’index de la chaîne de caractères source.
EDI
Le registre EDI est “l’inverse” du registre ESI. Il est utilisé pour conserver l’index de la chaîne de caractères de destination. Vous avez donc compris que ces deux registres sont souvent utilisés ensembles lors de copie et de comparaison de chaîne de caractères.
ESP
Ce registre possède un statut particulier. Il pointe normalement sur le haut de la pile d’exécution. Cette fameuse pile fera l’objet d’une attention particulière dans un article prochain lorsque nous parlerons des appels de fonctions.
EBP
Ce registre possède aussi un statut particulier. Il pointera, non pas sur le haut, mais bien sur le bas d’une trame de la pile d’exécution. Nous en reparlerons un peu plus tard.
Bien entendu, il faut garder à l’esprit que ces “normes” peuvent avoir des exception: c’est au programmeur d’utiliser les registres comme il le désire. Cependant, si vous utilisez les fonctionnalités d’un système d’exploitation vous devrez vous conformer aux normes en vigueur sur ce système.
Pointeur d’instruction EIP
EIP est un registre particulier. C’est le pointeur d’instructions. Ce registre est chargé de pointer vers la prochaine instruction à être exécutée. Pour faire une histoire courte, voici un graphique qui vous est familier, cette fois-ci, adapté pour montrer la position du registre EIP.

Vous avez donc compris que ce registre occupe un rôle très important puisque c’est par “lui” que “l’écoulement” des instruction sera faite.
L’article actuel s’intéresse à un dernier type de registre, les registres de segment. Ces registres ont une fonction particulière. Ils sont chargé de pointer vers les cases mémoires contenant les différents segments de l’application.
Registres de segments
De manière grossière, une application possède généralement trois segments. Le premier segment, le segment de code (CS) pointe vers la zone mémoire contenant le code de l’application. Le registre EIP pointera vers les intructions présentes dans ce segment afin de permettre au processeur d’exécuter ces instructions. Le deuxième segment, le segment de donnée (DS) pointe lui vers la zone mémoire qui contient les variable de l’application. Bref, comme son nom l’indique, il pointe vers les données de l’application. Le troisième segment de l’application pointe vers la pile d’exécution de l’application (SS), la stack. Nous parlerons de cette pile d’exécution plus en détails éventuellement. Les trois autres registres de segment sont des registres en “extra” qui peuvent être utilisés au besoin.
Ainsi s’achève la première semaine du mois de l’assembleur x86. Nous n’avons peut-être pas encore programmé en assembleur mais, une chose est certaine, le présent article représente le strict minimum des connaissances requise pour pouvoir commencer à programmer avec l’assembleur x86. Si vous avez bien compris cet article, vous n’aurez aucun mal pour la suite des choses!
Entre temps, jusqu’à la semaine prochaine, sentez-vous libre de nous contacter si jamais vous avez des questions! Pour ceux d’entre vous qui aimeraient suivre cette série et programmer les exercices qui seront présentés, vous pouvez déjà vous préparer une machine virtuelle Linux car c’est sous Linux que la suite de ce mois se déroullera. D’ici là, bonne semaine à tous!