Mois de l'assembleur x86, semaine 3 - Structures logiques
Le mois de Juin prend une saveur particulière cette année sur le blog du Hackfest, en effet, quatre articles sur la programmation assembleur seront publiés, un à chaque semaine, et le mois sera couronné d’une présentation HackerSpace sur le sujet. Espérons que vous y apprendrez quelque chose! Voici le troisième article de cette série sur le sujet. Les articles des semaine 1 et semaine 2 sont aussi disponibles.
Jusqu'a maintenant, tout ce que nous avons fait ne nous permet pas de faire des applications très élaborées. Nous avons parlé de la structure du processeur ainsi que de la structure de base des applications elles-mêmes. Aucune considération n’a encore été portée sur le contrôle logique de l’exécution d’une application. C’est aujourd’hui que les choses changent. Le thème aujourd’hui: contrôle du flux d’exécution de l’application.
Avant d’aller plus loin, un petit retour sur le premier article de la série s’impose. Comme nous discutons principalement du registre eip, je vous propose de prendre quelques minutes pour se remettre son fonctionnement en tête. Vous devriez tous reconnaître le graphique suivant.
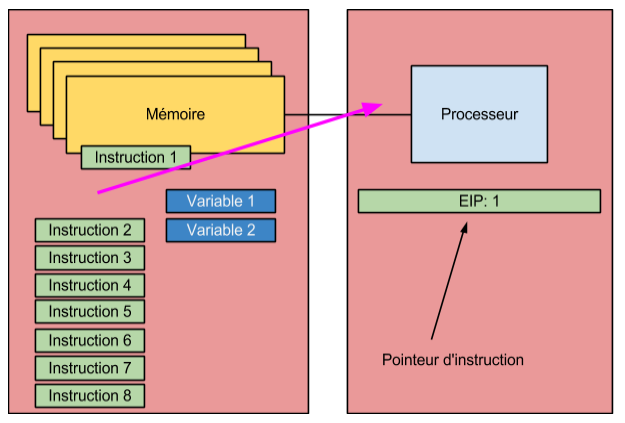
Tel que le montre le graphique précédent, le registre eip pointe sur la prochaine instruction devant être exécutée par le processeur. Ainsi, en réalité, lorsque nous allons modifier le cours logique du déroullement d’une application, nous modifierons, de manière détournée, la valeur du registre eip de manière à être en mesure de déterminer nous même la prochaine instruction devant être exécutée sans que le flo d’exécution soit linéaire. Pour commencer, afin de comprendre le flo d’exécution d’une application “plate” au sens qu’elle ne possède pas de variations, nous allons prendre l’application que nous avons programmée la semaine dernière. Cependant, afin d’avoir un visuel sur les adresses utilisées en cours d’exécution, nous allons désassembler le fichier binaire que nous avons préparé la semaine dernière. Pour effectuer le désassemblage, nous allons utiliser l’utilitaire objdump. Plus précisément, nous utiliserons l’option -D qui permet de désassembler toutes les section d’un fichier binaire. Le résultat de cette commande est montré à la figure suivante.
|
$ objdump -D movingDataProject movingDataProject: file format elf64-x86-64 Disassembly of section .text: 00000000004000b0 <_start>: 4000b0: b8 c8 00 60 00 mov $0x6000c8,%eax 4000b5: 67 83 00 32 addl $0x32,(%eax) 4000b9: 67 ff 00 incl (%eax) 4000bc: b8 01 00 00 00 mov $0x1,%eax 4000c1: bb 00 00 00 00 mov $0x0,%ebx 4000c6: cd 80 int $0x80 Disassembly of section .data: 00000000006000c8 : 6000c8: ff 00 incl (%rax) ... Disassembly of section .stab: 0000000000000000 : 0: 01 00 add %eax,(%rax) 2: 00 00 add %al,(%rax) 4: 00 00 add %al,(%rax) *****************************Code omis********************************* |
Comme vous pouvez le voir, l’ensemble des section de l’application ont été désassemblées. Dans notre cas, nous nous intéresserons seulement au label _start de la section .text. Vous remarquerez que les points où nous utilisions des adresses mémoires ont été modifiés et que ces adresses mémoires sont maintenant dans le code. Au moment de lier l’application, les labels ont été remplacé par les vraies adresses mémoires. Aussi, vous pouvez voir les adresses des instructions en début de ligne. Par exemple, l’instruction mov $0x6000c8, %eax est à l’adresse 4000b0. Avec le code désassemblé en main, nous allons lancer l’application à l’aide de gdb et mettre un point d’arrêt sur le label _start. Une fois arrivé au point d’arrêt, nous allons faire afficher la valeur des registres. La figure suivante montre l’ensemble des étapes décrites précédement.
|
$ gdb movingDataProject GNU gdb (Ubuntu/Linaro 7.4-2012.04-0ubuntu2.1) 7.4-2012.04 Copyright (C) 2012 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law. Type "show copying" and "show warranty" for details. This GDB was configured as "x86_64-linux-gnu". For bug reporting instructions, please see: Reading symbols from movingDataProject...done. (gdb) break _start Breakpoint 1 at 0x4000b0: file movingDataProject.s, line 18. (gdb) run Starting program:movingDataProject Breakpoint 1, _start () at movingDataProject.s:18 18 movl $nbPommes, %eax ←Prochaine ligne qui sera exécutée (gdb) info registers rax 0x0 0 rbx 0x0 0 rcx 0x0 0 rdx 0x0 0 rsi 0x0 0 rdi 0x0 0 rbp 0x0 0x0 rsp 0x7fffffffe1f0 0x7fffffffe1f0 r8 0x0 0 r9 0x0 0 r10 0x0 0 r11 0x200 512 r12 0x0 0 r13 0x0 0 r14 0x0 0 r15 0x0 0 rip 0x4000b0 0x4000b0 <_start> eflags 0x202 [ IF ] cs 0x33 51 ss 0x2b 43 ds 0x0 0 es 0x0 0 fs 0x0 0 gs 0x0 0 (gdb) |
N’oubliez pas, sur un système 64 bits, le registre eip porte le nom rip. L’analyse des informations de registre montre clairement que la prochaine instruction à être exécuté se trouve à l’adresse 4000b0. Laissez le programme s’exécuté étape par étape en observant la valeur du registre eip par rapport aux adresses inscrite dans la version désassemblée de l’application. Il sera facile de comprendre le lien entre le registre eip et la prochaine instruction à exécuter. Bon, passons aux choses “sérieuses”. Le but pour aujourd’hui est d’apprendre à implémenter des structures conditionnelles ainsi que des structures répétitives. Assez simple bref! Mais avec ces petits éléments, vous aurez ce qu’il faut en mains pour commencer à comprendre la logique des applications lorsque vous regardez le code assembleur de celles-ci.
Structure conditionnelle
La première structure dont nous allons parler, le if est assez simple à produire en assembleur. Par contre, afin de se donner une base de comparaison, nous allons commencer par écrire une version C de l’application test que nous allons développer en assembleur. Ainsi, commencez par programmer l’exemple suivant en C et compiler l’exemple (gcc -o fichier.c).
|
int nbPommes[2] = {200, 100}; int main(){ if (nbPommes[0] > nbPommes[1]){ nbPommes[0]++; } return 0; } |
L’application possède un tableau dans lequel deux chiffres sont présents. Si le premier indice est plus grand que le deuxième, le premier indice est incrémenté. Nous allons maintenant traduire cette application en assembleur. Voici le code assembleur pour une application très similaire.
|
.section .data nbPommes: .int 200, 100 .section .text .globl _start _start: movl $1, %esi movl nbPommes(,%esi,4), %eax cmpl %eax, nbPommes jle less incl nbPommes less: movl $1, %eax movl $0, %ebx int $0x80 |
La première chose que vous devriez remarquer dans cette application est la section .data qui comporte une déclaration dont nous n’avons pas parlé jusqu’à maintenant. En fait, déclarer une variable sous cette forme cause en réalité l’utilisation de plusieurs cases mémoires contigues. Bref, c’est comme si on avait fait un tableau en C. Dans le cas actuel, ce tableau contient les chiffres 200 et 100. La deuxième instruction inconnue est movl nbPommes(,%esi,4), %eax. Cette instruction permettant d’atteindre une plage mémoire se décompose comme suit:
adresseDeBase ( décallage, index, taille)
L’adresse de base est l’adresse à partir de laquelle l’instruction doit travailler. Le décallage représente un déplacement en mémoire à partir de l’adresse de base. Dans notre cas, comme nous ne voulons pas de décallage ce paramètre est laissé vide. L’index représente l’index dans le tableau de l’élément recherché et la taille représente la taille en octets des données devant être obtenues. Dans le cas actuelle, l’instruction permet d’atteindre le chiffre “100”. Ce chiffre est copié dans le registre eax. Arrive enfin la série d’instructions qui permet de traiter la condition. J’ai recoppié le code dans l’encadré suivant.
|
cmpl %eax, nbPommes jle less incl nbPommes less: movl $1, %eax movl $0, %ebx int $0x80 |
L’opération cmpl permet de comparer deux nombres. Dans le cas présent, le nombre contenu par le registre eax (100) est comparré au nombre qui se trouve dans le premier index de la variable nbPommes. Avec l’assembleur GNU, la comparaison est toujours faite selon la relation du deuxième nombre face au premier nombre (un peu plus dans un instant). L’instruction suivante, jle less permet de “sauter” au code situé au label “less” si la condition est respectée. Dans le cas actuel, la condition est “jle” donc “Jump Less or Equals”. Ainsi, si le deuxième nombre fournis à l’opérateur de comparaison est plus petit que le premier nombre, le saut sera fait et l’exécution continuera à partir du label “less”. Dans cette situation, la ligne suivant immédiatement la commande jle ne serait pas exécutée. Le tableau suivant montre une table de vérité appliquée à l’opérateur.
|
cmpl |
%eax |
nbPommes |
Résultat |
|
100 |
200 |
> | |
|
200 |
100 |
< | |
|
100 |
100 |
= |
Vous pouvez donc voir qu’en réalité, la lecture se fait de droite à gauche en ce qui concerne le résultat de l’opération cmpl. Aussi, remarquez que en raison de la philosophie de fonctionnement du langage, nous vérifions en réalité le “contraire” de ce que nous vérifions dans la version C de l’application. Vous êtes fortement encourragé à exécuter cette petite application avec différentes valeurs afin de vous faire une idée du fonctionnement des opérateurs de comparaisons.
En terminant cet exemple, la figure suivante présente le code désassemblé de la version C du petit programme montré en exemple. Bien entendu, il y a quelques différences, mais les concepts de base vus dans le présent exemple y sont présents.
|
00000000004004b4 : 4004b4: 55 push %rbp 4004b5: 48 89 e5 mov %rsp,%rbp 4004b8: 8b 15 5a 0b 20 00 mov 0x200b5a(%rip),%edx # 601018 4004be: 8b 05 58 0b 20 00 mov 0x200b58(%rip),%eax #60101c 4004c4: 39 c2 cmp %eax,%edx 4004c6: 7e 0f jle 4004d7 4004c8: 8b 05 4a 0b 20 00 mov 0x200b4a(%rip),%eax # 601018 4004ce: 83 c0 01 add $0x1,%eax 4004d1: 89 05 41 0b 20 00 mov %eax,0x200b41(%rip) # 601018 4004d7: b8 00 00 00 00 mov $0x0,%eax 4004dc: 5d pop %rbp 4004dd: c3 retq 4004de: 90 nop 4004df: 90 nop |
Avant d’aller plus loin, comme les instructions jump sont très importantes dans tous traitements logiques, voici une table qui présente les opérateurs de saut les plus fréquents.
|
Opérateur |
Signification |
|
je |
Jump equals |
|
jg |
Jump greater |
|
jge |
Jump greater or equals |
|
jl |
Jump less |
|
jle |
Jump less or equals |
|
jmp |
unconditional jump, always taken |
|
jz |
Jump if “Zero” flag is set |
Plusieurs autres instruction jump existent. Nous en parlerons en temps et lieux si besoin est.
La suite de l’article présente la structure if then else et les boucles. L’analyse précise du code n’est pas présentée. Cependant, la version C de l’application est toujours présentée suivant la version assembleur pour vous aider à analyser vous même le code. La meilleure solution reste, et de loin, l’analyse du code dans un débugueur. Cependant, n’oubliez pas d’observer la variation de la valeur du registre eip (rip) pendant l’opération de débuguage.
L’exemple de code suivant reprend l’exemple précédent. Cependant, dans l’éventualité où le deuxième index du tableau n’est pas plus petit que le premier, le deuxième élément est incrémenté.
|
.section .data nbPommes: .int 99, 100 .section .text .globl _start _start: nop movl $1, %esi movl nbPommes(,%esi,4), %eax cmpl %eax, nbPommes jle less incl nbPommes jmp end less: incl %eax movl %eax, nbPommes(,%esi,4) end: movl $1, %eax movl $0, %ebx int $0x80 |
int nbPommes[2] = {200, 100}; int main(){ if (nbPommes[0] > nbPommes[1]){ nbPommes[0]++; }else{ nbPommes[1]++; } return 0; } |
Maintenant, puisque l’assemblage (jeu de mot...) des structures logiques en assembleur se ressemble beaucoup pour l’ensemble de celles-ci, voici maintenant un exemple de comment une boucle pourrait être implémentée en assembleur. Cette fois, le code C n’est pas disponible! À vous d’en faire l’analyse! Mais attention, celui-ci demandera peut-être un brin de recherche de votre part ;)
|
.section .data nbPommes: .int 99, 100 .section .text .globl _start _start: nop movl $4, %ecx movl $0, %eax loop: addl %ecx, %eax decl %ecx jz end jmp loop end: movl $1, %eax movl $0, %ebx int $0x80 |
Voilà! C’est ainsi que se termine la semaine 3 du mois de l’assembleur x86! D’ici la semaine prochaine, en cas de questionnement, n’hésitez surtout pas à nous contacter!